|
本文介绍在Linux系统中安装和使用Photon抓取工具的方法,可以使用Photon抓取工具提取网站网址、电子邮件、文件和帐户。
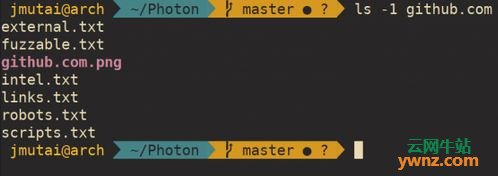
简介 Photon是一个用Python编写的令人难以置信的快速站点爬虫,用于从目标中提取网址,电子邮件,网站帐户等等,Photon能够处理每秒160个请求。 Photon能够在抓取时提取以下类型的数据: 提取范围内和范围外的URL以及带参数的URL。 其中包含JavaScript文件和端点。 可以根据自定义正则表达式模式提取字符串。 提取电子邮件,社交媒体帐户等。 提取文件:pdf,png,xml等。 Photon提取的数据以有组织的方式保存,比如 $ ls -1 X(X为一级域名网址) endpoints.txt external.txt files.txt fuzzable.txt intel.txt links.txt scripts.txt 所有文件都保存为文本以便于阅读。
相关链接
在Linux中安装和使用Photon Photon项目在git上可用,通过运行clone: $ git clone https://github.com/s0md3v/Photon.git Cloning into 'Photon'... remote: Counting objects: 417, done. remote: Compressing objects: 100% (22/22), done. remote: Total 417 (delta 20), reused 42 (delta 20), pack-reused 374 Receiving objects: 100% (417/417), 151.42 KiB | 201.00 KiB/s, done. Resolving deltas: 100% (182/182), done. 更改为Photon并开始使用Photon脚本: $ cd Photon $ chmod +x photon.py 使用选项--help时,会出来帮助页面,以下是可用选项: 用法:photon.py [options] 参考:在MacOS和Linux下直接运行.py文件的小方法。 选项: -u --url:root url -l --level:levels to crawl -t --threads:number of threads -d --delay:delay between requests -c --cookie:cookie -r --regex:regex pattern -s --seeds:additional seed urls -e --export:export formatted result -o --output:specify output directory --timeout:http requests timeout --ninja:ninja mode --update:update photon --dns:dump dns data --only-urls:only extract urls --user-agent:specify user-agent(s) 一个基本用法示例: $ ./photon.py -u https://github.com
-u选项用于指定根URL。 完成后,应创建具有站点名称的目录:
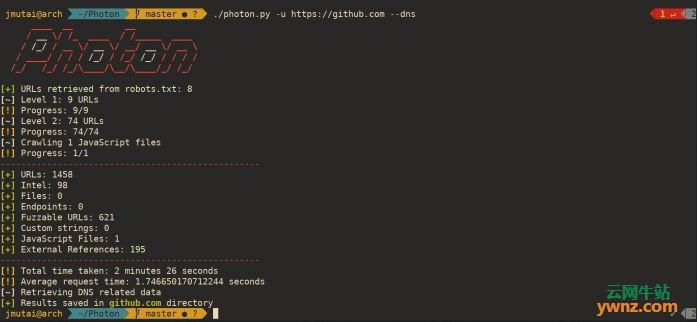
使用10个线程进行爬网,级别4并将数据导出为json: $ ./photon.py -u https://github.com -t 10 -l 3 --export=json 生成包含目标域的DNS数据的映像: $ ./photon.py -u http://example.com --dns 目前,如果目标是子域,则它不起作用。
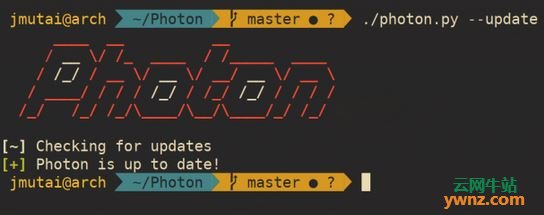
更新Photon的方法 要更新Photon,请运行以下命令: $ ./photon.py --update
相关主题 |