|
本文是翻译文章,主要讲 Linux 文件系统 EXT4 的历史发展点,让你更了解现在广泛被使用的 EXT4 文件系统,它被很多 Linux 发行版本默认使用。 在以前写的关于Linux文件系统的文章里,我写了一份说明书去介绍Linux文件系统,里面有一些高级的概念,比如说,一切都是文件。我很想去深入地讨论更多EXT文件系统的特性的信息。所以,首先让我们来回答这个问题:什么是文件系统?一个文件系统应该遵循以下特点: 1.数据存储:文件系统主要的功能是结构化存储和取回数据。 2.命名空间:提供一套命名和组织的方法,就是命名和结构化数据的规则。 3.安全模型:一种访问控制的策略。 4.API:系统操控文件系统对象的函数,就像操作文件夹和文件一样。 5.实现:一个实现以上功能的软件。 这篇文章集中与上面清单的第一项,还有探究元数据结构---在EXT文件系统中提供数据存储的逻辑框架。
EXT文件系统历史 虽然是为Linux编写的,但EXT文件系统起源于Minix操作系统,而Minix文件系统早在1987年首次发布,比Linux还早五年就已经发布了。如果我们查看EXT文件系统家族从其Minix根开始的历史和技术演变,就会更容易理解EXT4文件系统。
Minix 当编写原始Linux内核,Linus Torvalds需要一个文件系统,但是不想开发它。因此他简单的使用了Minix文件系统,这是 Andrew S. Tanenbaum开发的,而且是Tanenbaum 的Minix操作系统的一部分。Minix是类Unix操作系统,为教育使用而开发。它的代码开放使用,而且合理的授权给Torvalds,允许他将它用于Linux的初代版本。 Minix结构如下,其中大部分位于文件系统生成的分区中: 引导扇区(boot sector)安装于硬盘的第一个扇区。引导块(boot block)包含一个非常小的引导记录和一个分区表。 每一个分区中的第一个块是超级块(superblock),它包含了定义其他文件系统结构的元数据,并将它们定位在分配给分区的物理磁盘上。 节点位图块(inode bitmap block),它确定了哪个节点在使用以及哪个节点是空闲的。 节点(inodes),它们在磁盘上有它们自己的空间。每个节点包含了一个文件的信息,包括数据块的位置,即文件所属的区域。 区域位图(zone bitmap)跟踪记录数据区域的使用和释放。 数据区域(data zone),数据实际上存储的位置。 对于位图的两个类型来说,一个bit代表了一个特有的数据区域或者一个特有的节点。如果这个bit是0,这个区域或者节点是空闲的而且可供使用,但是如果这个bit是1,这个数据区域或者节点是在使用中的。 节点是什么?它是索引节点(index-node)的缩写,一个节点是在磁盘上的一个256字节的块,而且它存储文件相关的数据。这些数据包括文件的大小;文件的用户和所属组的用户ID;文件模式(即访问权限);以及三个时间戳具体说明了时间,包括:文件最后访问时间,最后修改时间,以及节点中的数据最后修改时间。 节点也包含了:指向硬盘上文件数据所在的位置。在Minix和EXT1-3文件系统中,它是一个数据区域和块的列表。Minix文件系统节点支持9个数据块,7个直接指针和2个间接指针。
EXT 最初的EXT文件系统(Extended)由Rémy Card编写,并于1992年与Linux一起发布,以规避Minix文件系统的一些大小限制。其中主要的结构变化是基于Unix文件系统(UFS)的文件系统元数据,该结构也被称为伯克利快速文件系统(FFS)。我发现很少有关于此EXT文件系统的可考究的发布信息,显然是因为它存在重大问题,并很快被EXT2文件系统所取代。
EXT2 EXT2文件系统非常成功。它在Linux发行版中被使用了很多年,并且它是我在1997年左右开始使用Red Hat Linux 5.0时遇到的第一个文件系统。EXT2文件系统与EXT文件系统具有基本相同的元数据结构,但EXT2更具前瞻性,因为在元数据结构之间保留大量磁盘空间以供未来使用。 像Minix一样,EXT2在其安装的硬盘的第一个扇区中有一个引导扇区,其中包括一个非常小的引导记录和一个分区表。在引导扇区后面有一些预留空间,它跨越引导记录和硬盘上通常位于下一个柱面边界上的第一个分区之间的空间。 GRUB2(可能还有GRUB1)使用这个空间作为其启动代码的一部分。 每个EXT2分区中的空间被划分为多个柱面组,可以更加精细地管理数据空间。 根据我的经验,组大小通常约为8MB。下面的图1显示了柱面组的基本结构。柱面中的数据分配单元是块,其大小通常为4K。
图1:EXT文件系统中柱面组的结构 柱面组中的第一个块是一个超级块,它包含定义其他文件系统结构并将其定位在物理磁盘上的元数据。分区中的一些附加组将具有备份超级块,但不是全部。损坏的超级块可以使用dd等磁盘实用程序将备份超级块的内容复制到主超级块。它并不经常发生,但是多年前曾经有一个受损的超级块,我可以使用其中一个备份超级块来恢复其内容。幸运的是,我已经预见到并使用dumpe2fs命令转储我系统上分区的描述符信息。 下面是dumpe2fs命令的部分输出。它显示了超级块中包含的元数据,以及关于文件系统中前两个柱面组的数据。 # dumpe2fs /dev/sda1 Filesystem volume name: boot Last mounted on: /boot Filesystem UUID: 79fc5ed8-5bbc-4dfe-8359-b7b36be6eed3 Filesystem magic number: 0xEF53 Filesystem revision #: 1 (dynamic) Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file dir nlink extra_isize Filesystem flags: signed_directory_hash Default mount options: user_xattr acl Filesystem state: clean Errors behavior: Continue Filesystem OS type: Linux Inode count: 122160 Block count: 488192 Reserved block count: 24409 Free blocks: 376512 Free inodes: 121690 First block: 0 Block size: 4096 Fragment size: 4096 Group descriptor size: 64 Reserved GDT blocks: 238 Blocks per group: 32768 Fragments per group: 32768 Inodes per group: 8144 Inode blocks per group: 509 Flex block group size: 16 Filesystem created: Tue Feb 7 09:33:34 2017 Last mount time: Sat Apr 29 21:42:01 2017 Last write time: Sat Apr 29 21:42:01 2017 Mount count: 25 Maximum mount count: -1 Last checked: Tue Feb 7 09:33:34 2017 Check interval: 0 (<none>) Lifetime writes: 594 MB Reserved blocks uid: 0 (user root) Reserved blocks gid: 0 (group root) First inode: 11 Inode size: 256 Required extra isize: 32 Desired extra isize: 32 Journal inode: 8 Default directory hash: half_md4 Directory Hash Seed: c780bac9-d4bf-4f35-b695-0fe35e8d2d60 Journal backup: inode blocks Journal features: journal_64bit Journal size: 32M Journal length: 8192 Journal sequence: 0x00000213 Journal start: 0 Group 0: (Blocks 0-32767) Primary superblock at 0, Group descriptors at 1-1 Reserved GDT blocks at 2-239 Block bitmap at 240 (+240) Inode bitmap at 255 (+255) Inode table at 270-778 (+270) 24839 free blocks, 7676 free inodes, 16 directories Free blocks: 7929-32767 Free inodes: 440, 470-8144 Group 1: (Blocks 32768-65535) Backup superblock at 32768, Group descriptors at 32769-32769 Reserved GDT blocks at 32770-33007 Block bitmap at 241 (bg #0 + 241) Inode bitmap at 256 (bg #0 + 256) Inode table at 779-1287 (bg #0 + 779) 8668 free blocks, 8142 free inodes, 2 directories Free blocks: 33008-33283, 33332-33791, 33974-33975, 34023-34092, 34094-34104, 34526-34687, 34706-34723, 34817-35374, 35421-35844, 35935-36355, 36357-36863, 38912-39935, 39940-40570, 42620-42623, 42655, 42674-42687, 42721-42751, 42798-42815, 42847, 42875-42879, 42918-42943, 42975, 43000-43007, 43519, 43559-44031, 44042-44543, 44545-45055, 45116-45567, 45601-45631, 45658-45663, 45689-45695, 45736-45759, 45802-45823, 45857-45887, 45919, 45950-45951, 45972-45983, 46014-46015, 46057-46079, 46112-46591, 46921-47103, 49152-49395, 50027-50355, 52237-52255, 52285-52287, 52323-52351, 52383, 52450-52479, 52518-52543, 52584-52607, 52652-52671, 52734-52735, 52743-53247 Free inodes: 8147-16288 Group 2: (Blocks 65536-98303) Block bitmap at 242 (bg #0 + 242) Inode bitmap at 257 (bg #0 + 257) Inode table at 1288-1796 (bg #0 + 1288) 6326 free blocks, 8144 free inodes, 0 directories Free blocks: 67042-67583, 72201-72994, 80185-80349, 81191-81919, 90112-94207 Free inodes: 16289-24432 Group 3: (Blocks 98304-131071) 每个柱面组都有自己的inode位图,该位图用于确定使用哪些inode,以及该组中哪些是空闲的。inode在每个组中都有自己的空间。每个inode都包含有关一个文件的信息,包括属于该文件的数据块的位置。块位图跟踪文件系统中使用和释放的数据块。注意,上面显示的输出中有大量关于文件系统的数据。在很大的文件系统中,组数据可以长达数百页。组元数据包括组中所有空闲数据块的列表。 EXT文件系统实现了保证文件碎片最小化的数据分配策略。减少磁盘碎片化可改善文件系统的性能。这些策略将在下文的EXT4部分中进行介绍。 在某些情况下,我曾遇到的EXT2文件系统的最大问题是在崩溃后可能需要几个小时才能恢复,因为fsck(file system check)程序需要很长时间才能找到并纠正文件系统中的任何不一致。它曾在我的一台计算机上花费了28个小时的时间,以实现在发生崩溃到重新启动时完全恢复磁盘 -并且这是在磁盘大小为数百兆字节下测试的结果。
EXT3 EXT3文件系统的唯一目标是克服fsck程序需要大量时间来完全恢复因文件更新操作期间发生的不正确关闭而损坏的磁盘结构的问题。EXT文件系统的唯一增加是journal,它预先记录了将对文件系统执行的改动。磁盘结构的其余部分和EXT2中是相同的。 EXT3中的journal并不是直接将数据写入磁盘的数据区域,而是将文件数据及其元数据写入到磁盘上的指定区域。一旦数据安全地存储在硬盘上,它就可以合并到目标文件或附加到目标文件中,而这几乎不会丢失数据。由于该数据被提交到磁盘的数据区域,因此需更新journal以便在发生系统故障时文件系统保持一致状态,然后该journal中的所有数据都被提交。在下次启动时,将检查文件系统是否存在不一致性,然后将journal中剩余的数据提交到磁盘的数据区域以完成对目标文件的更新。 日志化确实会降低数据写入性能,但journal提供了三种选项可供用户在性能,数据完整性和安全性之间进行选择。我的个人偏好是安全性,因为我的环境不需要繁重的磁盘写入操作。 日志函数最多可以减少在检查硬盘驱动发现不一致性所需的时间:从几小时(甚至几天)到几分钟不等。多年来,我遇到了很多导致系统崩溃的问题。个中细节可以填满另一篇文章,但足以证实大多数是自我原因造成的,就像踢掉电源插头一样。幸运的是,EXT日志化文件系统已将启动恢复时间缩短到两三分钟。另外,自从我开始使用带日志功能的EXT3以来,我从来没有遇到丢失数据的问题了。 EXT3的日志功能可以关闭,然后作为EXT2文件系统运行。日志功能本身仍然存在,它是空的并且是未使用的。只需使用mount命令重新挂载分区,使用type参数指定EXT2。您可以在命令行中执行此操作,这取决于您使用的是哪个文件系统,但是您可以更改/etc/fstab文件中的类型说明符,然后重新启动。我强烈建议不要将EXT3文件系统作为EXT2使用,因为可能会丢失数据并延长恢复时间。 现有的EXT2文件系统可以通过使用以下命令添加日志来升级到EXT3。 tune2fs -j /dev/sda1 其中/dev/sda1是驱动器和分区标识符。确保在/etc/fstab中更改文件类型说明符,并重新启动分区或重新启动系统以使更改生效。
EXT4 EXT4文件系统主要改善了性能,可靠性和容量。为了提升可靠性,添加了元数据和日志校验和。为了完成各种各样的关键任务的需求,文件系统时间戳将时间间隔精确到了纳秒。时间戳字段的两个高位bit将2038年问题延续到了2446年——至少为EXT4文件系统延续了。 在EXT4中,数据分配从固定块变成了扩展块。一个扩展块通过它在硬盘上的起始和结束位置来描述。这使得在一个单一节点指针条目中描述非常长的物理连续文件成为可能,它可以显著减少大文件中的描述所有数据的位置的所需指针的数量。为了进一步减少碎片化,其他分配策略已经在EXT4中实现。 EXT4通过在磁盘上分散新创建的文件来减少碎片化,因此他们不会像早期的PC文件系统,聚集在磁盘的起始位置。文件分配算法尝试尽量将文件均匀的覆盖到柱面组,而且当不得不产生碎片时,尽可能地将间断文件范围靠近同一个文件的其他碎片,来尽可能压缩磁头寻找和旋转等待时间。当一个新文件创建的时候或者当一个已有文件扩大的时候,附加策略用于预分配额外磁盘空间。它有助于保证扩大文件不会导致它直接变为碎片。新文件不会直接分配在已存在文件的后面,这也阻止了已存在文件的碎片化。 除了数据在磁盘的具体位置,EXT4使用一些功能策略,例如延迟分配,允许文件系统在分配空间之前先收集到要写到磁盘的所有数据。这可以提高数据空间连续的概率。 之前的EXT文件系统,例如EXT2和EXT3,可以挂载EXT4,来提升一些次要性能。不幸的是,它要求关掉一些EXT4的重要的新特性,因此我不建议这种做法。 从Fedora 14开始,EXT4已经是Fedora的默认文件系统。使用在Fedroa文档描述的过程,一个EXT3文件系统可以升级到EXT4,然而由于剩余的EXT3元数据结构,它的性能仍然会受到影响。从EXT3升级到EXT4最好的方法是备份所有的目标文件系统分区的数据,使用mkfs命令将一个空的EXT4文件系统写到分区,然后从备份恢复所有数据。
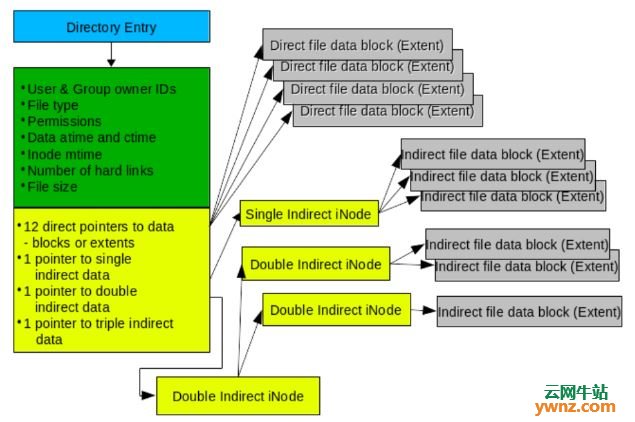
节点(Inode) 在之前描述过,节点是一个EXT文件系统的元数据的关键要素。图2展示了节点和存储在硬盘上的数据之间的关系。这个示意图是目录和单一文件的节点,在这种情况下,可能是高度碎片化文件的节点。EXT文件系统为减少碎片化而积极努力,因此你不会看到有很多间接数据块或者数据区的文件。事实上,就像你将在下面看到的,碎片化在EXT文件系统中非常少见,因此大多节点会只用一个或者两个直接数据指针而且不使用间接指针。
图2:节点存储了关于每个文件的信息和EXT文件系统对所有属于它的数据的定位。 节点不包含文件的名称。通过目录项(directory entry)来访问文件,它自己就是文件的名称而且包含指向此节点的指针。指针的值是节点号。每个文件系统中的节点都有一个唯一的ID号,但是在同一个电脑(甚至同一个硬盘)的其他文件系统中的节点可以有相同的节点号。这会对硬连接产生一些后果,这方面内容超出了本文的范围。 节点包含了文件的元数据,包括它的类型和权限以及它的大小。节点也包含了15个指针的空间,来描述柱面组中数据部分中的数据块或数据区的位置和长度。12个指针提供了数据区的直接访问,而且对处理大部分文件都是足够的。然而,对于有大量碎片的文件,它可能必须需要一些额外的空间,以间接节点的形式描述。从技术上来讲,它们不是真正的节点,因此为了方便我使用短语“间接节点(node)”。 间接节点是文件系统中一个常规的数据块,只用于描述数据而且不用存储元数据,因此可以支持超过15个指针。例如,一个大小为4K的块可以支持512个4字节间接节点,允许一个单一文件包含12(直接)+512(间接)=524个区。同样也支持双重或三重间接节点,但是我们一般不太可能遇到需要这么多区的文件。
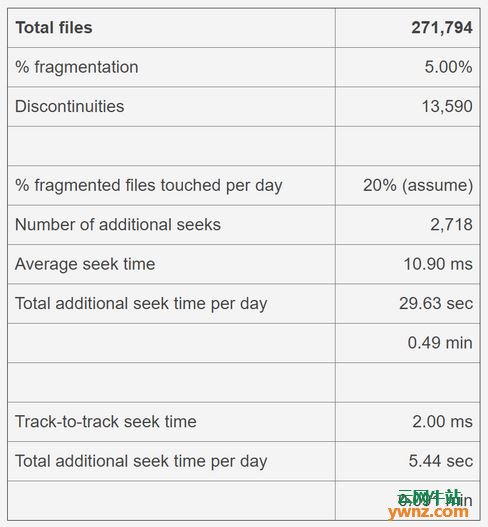
数据碎片 对于许多陈旧的PC文件系统(诸如FAT(及其所有变体)和NTFS),碎片化一直是导致磁盘性能下降的主要问题。碎片整理本身就成为一个行业,囊括不同品牌的碎片整理软件,其作用从非常有效到表现平平。 Linux扩展文件系统使用的数据分配策略,有助于最大限度地减少硬盘驱动器上文件的碎片,并在碎片发生时减少碎片效应。你可以在EXT文件系统上使用fsck命令来检查整个文件系统的碎片。以下示例检查我的主工作站的主目录,该目录仅有1.5%碎片化。请务必使用-n参数,因为它可以防止fsck对所扫描的文件系统执行任何操作。 fsck -fn /dev/mapper/vg_01-home 我曾经进行过一些理论上的计算,以确定磁盘碎片整理是否会导致性能显着提高。虽然我确实做了一些假定,但我使用的磁盘性能数据来自新的300GB,Western Digital硬盘,具有2.0ms的磁轨间寻址时间。本例中的文件数量是我在计算当天存在于该文件系统中的实际数量。我确实假定每天都会触发相当多的碎片文件(20%)。
表1: 碎片化对磁盘性能的理论上的影响 我已经做了两次测算,每天总的附加寻址时间,一次是基于磁轨间寻址时间,这是由于EXT文件分配策略而导致大多数文件更可能出现的情况,另一种是平均寻址时间,我假定这会触发相当于最坏的情形。 从表1可以看出,对于具有相当性能的硬盘驱动器的现代EXT文件系统来说,碎片化影响最小;对绝大多数应用程序来说可以忽略不计。你可以将实际环境中的数据插入到你自己的类似电子表格中,以得到你对性能影响的预期。这种计算方式很可能不会代表实际性能,但它可以提供对碎片话及其对系统的理论上的影响的一些洞察力。 我的大部分分区大约1.5%或1.6%碎片化;我确实有一个3.3%碎片化的分区,但这是一个大的,128GB的文件系统,拥有少于100个非常大的ISO映像文件;多年来,我不得不多次扩展此分区,因为它太满了。 这并不是说某些应用程序环境不需要更少的碎片文件的保证。EXT文件系统可以由知识渊博的管理员进行调整,他们可以调整参数以补偿特定的工作负载类型。这可以在文件系统被创建时或之后使用tune2fs命令来完成。应对每次调优改动的结果进行测试,细致地记录并进行分析,以确保对目标环境达到最佳性能。在最差的情况下,如果性能无法提升到所需的水平,则可能有更适合特定工作负载的其他文件系统类型。请记住,在单个主机系统上混用文件系统类型以匹配每个文件系统上的负载是很常见的。 由于在大多数EXT文件系统中碎片数量很少,因此不需要进行碎片整理。无论如何,EXT文件系统都没有安全的碎片整理工具。目前有几个工具可以让你检查单个文件的碎片状况或文件系统中剩余空闲空间的碎片化状态。有一个工具,e4defrag,它将在可用空间允许的前提下对文件、目录或文件系统进行尽可能地碎片化整理。顾名思义,它只适用于EXT4文件系统中的文件,并且存在一些局限性。 如果有必要对EXT文件系统执行完全的碎片整理,则仅有一种方法可以可靠地工作。你必须移动文件系统中的所有文件以进行碎片整理,以确保在将文件安全复制到其他位置后将其删除。如果可能的话,你可以增加文件系统的大小来辅助减少将来的碎片产生。然后将文件复制回目标文件系统。即使这样做并不能保证所有的文件都会被完全去碎片化。
结论 20多年来,EXT文件系统一直是许多Linux发行版的默认文件系统。它们需要少量的维护就能提供稳定性、高容量、可靠性和性能。我尝试过其他文件系统,但总是回到EXT。毫无疑问,EXT4文件系统应该用于大多数Linux系统,除非有令人信服的理由去使用另一个文件系统。
关于本文作者 David Both。David Both居住在北卡罗来纳州的Raleigh,是Linux和开源的支持者。他在IT行业工作了四十多年,并在IBM教授OS/2了二十多年。在IBM工作期间,他在1981年为最初的IBM PC编写了第一期培训课程。他曾为红帽教授RHCE课程,并曾在MCI Worldcom,思科和北卡罗莱纳州工作。他在Linux和开源软件方面工作了近20年。David为OS/2杂志,Linux杂志,Linux周刊和OpenSource.com选写了文章。他与思科同事合作撰写的文章“Complete Kickstart”在2008年Linux杂志十大最佳系统管理文章排行榜中名列第九。
相关主题 |