|
在内存地址上设置断点虽然不错,但它并没有提供最方便用户的工具。我们希望能够在源代码行和函数入口地址上设置断点,以便我们可以在与代码相同的抽象级别中进行调试。 这篇文章将会添加源码级断点到我们的调试器中。通过所有我们已经支持的功能,这要比起最初听起来容易得多。我们还将添加一个命令来获取符号的类型和地址,这对于定位代码或数据以及理解链接概念非常有用。
系列文章索引 1.准备环境 2.断点 3.寄存器和内存 5.源码和信号 6.源码层逐步执行 7.源码层断点 8.调用栈 9.读取变量 10.之后步骤
断点 DWARF Elves和dwarves 这篇文章,描述了 DWARF 调试信息是如何工作的,以及如何用它来将机器码映射到高层源码中。回想一下,DWARF 包含了函数的地址范围和一个允许你在抽象层之间转换代码位置的行表。我们将使用这些功能来实现我们的断点。
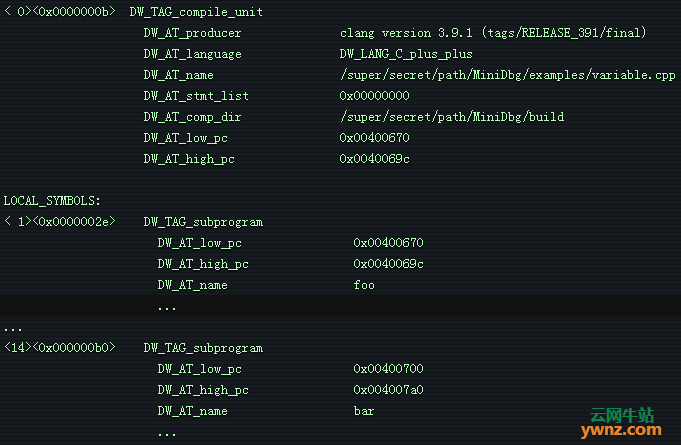
函数入口 如果你考虑重载、成员函数等等,那么在函数名上设置断点可能有点复杂,但是我们将遍历所有的编译单元,并搜索与我们正在寻找的名称匹配的函数。DWARF 信息如下所示:
我们想要匹配 DW_AT_name 并使用 DW_AT_low_pc(函数的起始地址)来设置我们的断点。 void debugger::set_breakpoint_at_function(const std::string& name) { for (const auto& cu : m_dwarf.compilation_units()) { for (const auto& die : cu.root()) { if (die.has(dwarf::DW_AT::name) && at_name(die) == name) { auto low_pc = at_low_pc(die); auto entry = get_line_entry_from_pc(low_pc); ++entry; //skip prologue set_breakpoint_at_address(entry->address); } } } } 这代码看起来有点奇怪的唯一一点是 ++entry。 问题是函数的 DW_AT_low_pc 不指向该函数的用户代码的起始地址,它指向 prologue 的开始。编译器通常会输出一个函数的 prologue 和 epilogue,它们用于执行保存和恢复堆栈、操作堆栈指针等。这对我们来说不是很有用,所以我们将入口行加一来获取用户代码的第一行而不是 prologue。DWARF 行表实际上具有一些功能,用于将入口标记为函数 prologue 之后的第一行,但并不是所有编译器都输出它,因此我采用了原始的方法。
源码行 要在高层源码行上设置一个断点,我们要将这个行号转换成 DWARF 中的一个地址。我们将遍历编译单元,寻找一个名称与给定文件匹配的编译单元,然后查找与给定行对应的入口。 DWARF 看上去有点像这样: .debug_line: line number info for a single cu Source lines (from CU-DIE at .debug_info offset 0x0000000b): NS new statement, BB new basic block, ET end of text sequence PE prologue end, EB epilogue begin IS=val ISA number, DI=val discriminator value <pc>[lno,col] NS BB ET PE EB IS= DI= uri: "filepath" 0x004004a7 [ 1, 0] NS uri: "/super/secret/path/a.hpp" 0x004004ab [ 2, 0] NS 0x004004b2 [ 3, 0] NS 0x004004b9 [ 4, 0] NS 0x004004c1 [ 5, 0] NS 0x004004c3 [ 1, 0] NS uri: "/super/secret/path/b.hpp" 0x004004c7 [ 2, 0] NS 0x004004ce [ 3, 0] NS 0x004004d5 [ 4, 0] NS 0x004004dd [ 5, 0] NS 0x004004df [ 4, 0] NS uri: "/super/secret/path/ab.cpp" 0x004004e3 [ 5, 0] NS 0x004004e8 [ 6, 0] NS 0x004004ed [ 7, 0] NS 0x004004f4 [ 7, 0] NS ET 所以如果我们想要在 ab.cpp 的第五行设置一个断点,我们将查找与行 (0x004004e3) 相关的入口并设置一个断点。 void debugger::set_breakpoint_at_source_line(const std::string& file, unsigned line) { for (const auto& cu : m_dwarf.compilation_units()) { if (is_suffix(file, at_name(cu.root()))) { const auto& lt = cu.get_line_table(); for (const auto& entry : lt) { if (entry.is_stmt && entry.line == line) { set_breakpoint_at_address(entry.address); return; } } } } } 我这里做了 is_suffix hack,这样你可以输入 c.cpp 代表 a/b/c.cpp 。当然你实际上应该使用大小写敏感路径处理库或者其它东西,但是我比较懒。entry.is_stmt 是检查行表入口是否被标记为一个语句的开头,这是由编译器根据它认为是断点的最佳目标的地址设置的。
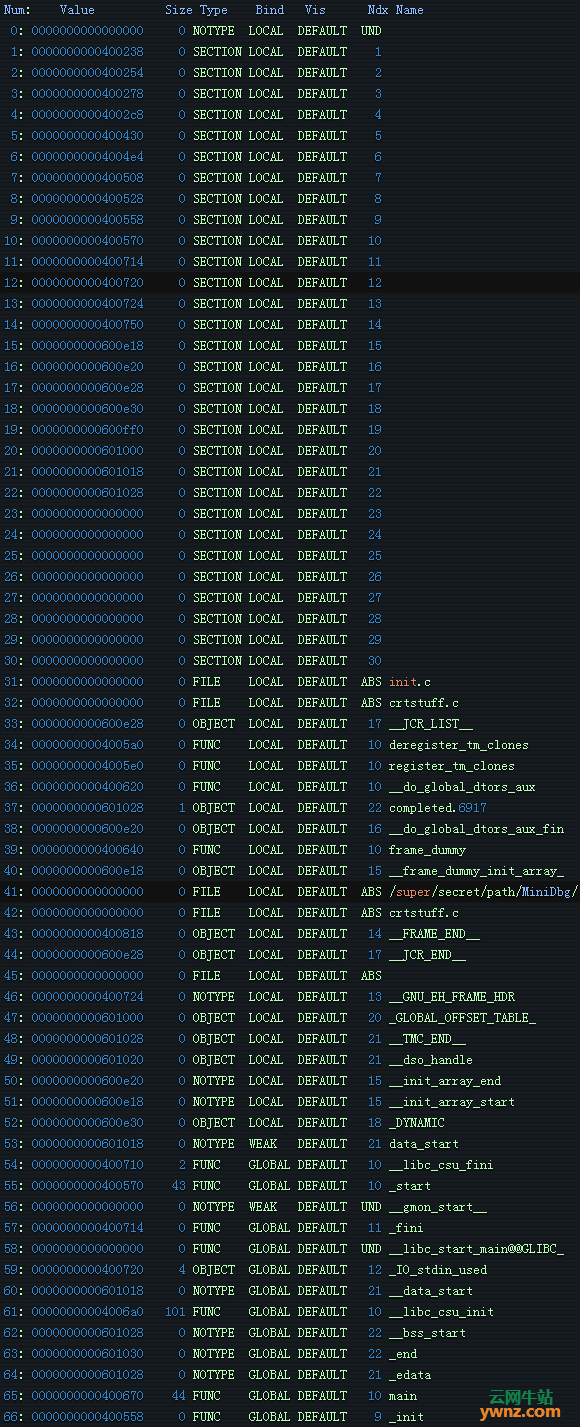
符号查找 当我们在对象文件层时,符号是王者。函数用符号命名,全局变量用符号命名,你得到一个符号,我们得到一个符号,每个人都得到一个符号。 在给定的对象文件中,一些符号可能引用其他对象文件或共享库,链接器将从符号引用创建一个可执行程序。 可以在正确命名的符号表中查找符号,它存储在二进制文件的 ELF 部分中。幸运的是,libelfin 有一个不错的接口来做这件事,所以我们不需要自己处理所有的 ELF 的事情。为了让你知道我们在处理什么,下面是一个二进制文件的 .symtab 部分的转储,它由 readelf 生成:
你可以在对象文件中看到用于设置环境的很多符号,最后还可以看到 main 符号。 我们对符号的类型、名称和值(地址)感兴趣。我们有一个该类型的 symbol_type 枚举,并使用一个 std::string 作为名称,std::uintptr_t 作为地址: enum class symbol_type { notype, // No type (e.g., absolute symbol) object, // Data object func, // Function entry point section, // Symbol is associated with a section file, // Source file associated with the }; // object file std::string to_string (symbol_type st) { switch (st) { case symbol_type::notype: return "notype"; case symbol_type::object: return "object"; case symbol_type::func: return "func"; case symbol_type::section: return "section"; case symbol_type::file: return "file"; } } struct symbol { symbol_type type; std::string name; std::uintptr_t addr; }; 我们需要将从 libelfin 获得的符号类型映射到我们的枚举,因为我们不希望依赖关系破环这个接口。幸运的是,我为所有的东西选了同样的名字,所以这样很简单: symbol_type to_symbol_type(elf::stt sym) { switch (sym) { case elf::stt::notype: return symbol_type::notype; case elf::stt::object: return symbol_type::object; case elf::stt::func: return symbol_type::func; case elf::stt::section: return symbol_type::section; case elf::stt::file: return symbol_type::file; default: return symbol_type::notype; } }; 最后我们要查找符号。为了说明的目的,我循环查找符号表的 ELF 部分,然后收集我在其中找到的任意符号到 std::vector 中。更智能的实现可以建立从名称到符号的映射,这样你只需要查看一次数据就行了。 std::vector<symbol> debugger::lookup_symbol(const std::string& name) { std::vector<symbol> syms; for (auto &sec : m_elf.sections()) { if (sec.get_hdr().type != elf::sht::symtab && sec.get_hdr().type != elf::sht::dynsym) continue; for (auto sym : sec.as_symtab()) { if (sym.get_name() == name) { auto &d = sym.get_data(); syms.push_back(symbol{to_symbol_type(d.type()), sym.get_name(), d.value}); } } } return syms; }
添加命令 一如往常,我们需要添加一些更多的命令来向用户暴露功能。对于断点,我使用 GDB 风格的接口,其中断点类型是通过你传递的参数推断的,而不用要求显式切换: 0x<hexadecimal> -> 断点地址 <line>:<filename> -> 断点行号 <anything else> -> 断点函数名 else if(is_prefix(command, "break")) { if (args[1][0] == '0' && args[1][1] == 'x') { std::string addr {args[1], 2}; set_breakpoint_at_address(std::stol(addr, 0, 16)); } else if (args[1].find(':') != std::string::npos) { auto file_and_line = split(args[1], ':'); set_breakpoint_at_source_line(file_and_line[0], std::stoi(file_and_line[1])); } else { set_breakpoint_at_function(args[1]); } } 对于符号,我们将查找符号并打印出我们发现的任何匹配项: else if(is_prefix(command, "symbol")) { auto syms = lookup_symbol(args[1]); for (auto&& s : syms) { std::cout << s.name << ' ' << to_string(s.type) << " 0x" << std::hex << s.addr << std::endl; } }
测试一下 在一个简单的二进制文件上启动调试器,并设置源代码级别的断点。在一些 foo 函数上设置一个断点,看到我的调试器停在它上面是我这个项目最有价值的时刻之一。 符号查找可以通过在程序中添加一些函数或全局变量并查找它们的名称来进行测试。请注意,如果你正在编译 C++ 代码,你还需要考虑名称重整。 本文就这些了。下一次我将展示如何向调试器添加堆栈展开支持。 你可以在这里找到这篇文章的代码。 |