|
腾讯万亿级维度特性计算Angel 2.0已经面世,同时腾讯已携Angel 2.0加入了LF深度学习基金会,结合基金会成熟的运营,全面升级的Angel 2.0将与国际开源社区继续深入互动,致力于让机器学习技术更易于上手研究及应用落地的目标。关于腾讯加入LF深度学习基金会的新闻请看Linux基金会推出LF深度学习基金会,腾讯华为等加入。
Angel简介
1.Angel是一个基于参数服务器(Parameter Server)理念开发的高性能分布式机器学习平台,它基于腾讯内部的海量数据进行了反复的调优,并具有广泛的适用性和稳定性,模型维度越高,优势越明显。 Angel由腾讯和北京大学联合开发,兼顾了工业界的高可用性和学术界的创新性。 2.Angel的核心设计理念围绕模型。它将高维度的大模型合理切分到多个参数服务器节点,并通过高效的模型更新接口和运算函数,以及灵活的同步协议,轻松实现各种高效的机器学习算法。 3.Angel基于Java和Scala开发,能在社区的Yarn上直接调度运行,并基于PS Service,支持Spark on Angel,集成了部分图计算和深度学习算法。
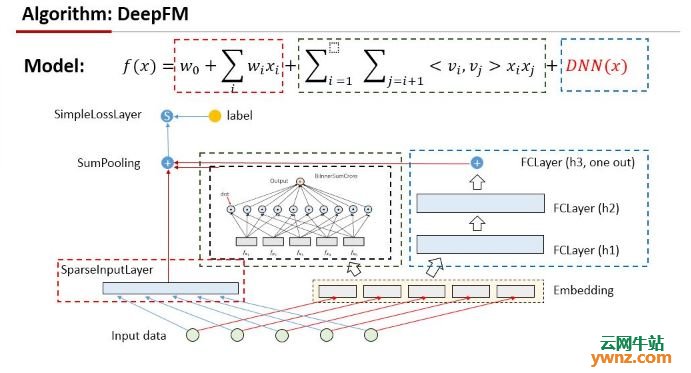
初步了解Angel 2.0 1.Angel具有广泛的适用性和稳定性,模型维度越高时,平台便有越明显的优势。进入Angel 2.0,凭借参数服务器的支持,Angel可以轻松扩展到千亿级维度特性。同时,通过全面优化的算法,Angel 2.0将pulling/pushing子模型引入高维模型,在支持以高维度模型为代表的高性能数学库上,展现出优异的性能。 2.在兼容方面,Angel基于 Java 和 Scala开发,通过Yarn进行调度运行,提供了丰富的优化方法和机器学习算法实现。配套PS Service,Angel支持Spark 或其它图计算、深度学习框架。而Angel 2.0在深度学习的支持上也做出重要优化,如对DeepFM,PNN,Wide&Deep,NFM等常见深度学习框架的全面兼容,以及支持用户通过Json定义的网络。
Angel 2.0特性介绍 一、万亿级维度特性计算 1)基于参数服务器,Angel可以轻松扩展到万亿级维度的模型 2)针对稀疏大模型的场景, Angel对底层数数学库进行了做了优化 3)Angel上的算法通过pulling/pushing子模型, 轻松训练万亿级维度的模型 二、高性能数学库 1)无泛型设计, 采用Java基础数据类型来加速计算 2)使用快速哈希方法,加速稀疏向量/矩阵运算 3)Long-Key索引和Compoent量向量/矩阵的引入, 使Angel支持超大模型 4)Execotor-Expression架构使其基础运算高效且易于扩展 三、计算图支持 1)基于层的轻量计算图 2)自动计算梯度 3)易于添加层以扩展系统 4)开箱即用的特征交叉层,有利于推荐系统算法开发 5)Angel和Spark on Angel共享统一的计算图 四、深度学习支持 1)推荐系统中常见的深度学习算法,如Deep And Wide, DeepFM,PNN,PNN,NFM都已支持 2)用户可以通过Json定义的网络
Angel编译指南 1.编译环境依赖 Jdk >= 1.8 Maven >= 3.0.5 Python >=3.6 如果要运行PyAngel Protobuf >= 2.5.0 需与hadoop环境自带的protobuf版本保持一致。目前hadoop官方发布包使用的是2.5.0版本,所以推荐使用2.5.0版本,除非你自己使用更新的protobuf版本编译了hadoop 2.源码下载 git clone https://github.com/tencent/angel 3.编译 进入源码根目录,执行命令: mvn clean package -Dmaven.test.skip=true 编译完成后,在源码根目录dist/target目录下会生成一个发布包:angel-${version}-bin.zip 4.发布包 发布包解压后,根目录下有几个子目录: bin: Angel任务提交脚本 conf:系统配置文件 data:简单测试数据 lib:Angel的jar包 & 依赖jar包 python:Python相关脚本
本地运行模式 本地运行模式主要用于测试功能是否正确。目前本地运行模式仅支持一个Worker(可以有多个Task)和一个PS。可以通过配置选项angel.deploy.mode来使用本地运行模式。 1.运行环境准备 Java >= 1.8 Angel发布包 angel-<version>-bin.zip 配置好HADOOP_HOME和JAVA_HOME环境变量,解压Angel发布包,就可以以LOCAL模式运行Angel任务了。 2.LOCAL 运行例子 发布包解压后,在根目录下有一个bin目录,提交任务相关的脚本都放在该目录下。例如运行简单的逻辑回归的例子: ./angel-example com.tencent.angel.example.ml.LogisticRegLocalExample
Angel On Yarn运行 由于业界很多公司的大数据平台,都是基于Yarn搭建,所以Angel目前的分布式运行是基于Yarn,方便用户复用现网环境,而无需任何修改。 鉴于Yarn的搭建步骤和机器要求,不建议在小机器上,进行尝试该运行。如果一定要运行,最少需要6G的内存(1ps+1worker+1am),最好有10G的内存,比较宽裕。 1.运行环境准备 Angel的分布式Yarn运行模式需要的环境,其实也非常简单: 1].一个可以正常运行Hadoop集群,包括Yarn和HDFS Hadoop >= 2.2.0 2].一个用于提交Angel任务的客户端Gateway Java >= 1.8 可以正常提交Hadoop的MR作业 Angel发布包:angel-<version>-bin.zip 2.Angel任务运行示例 以最简单的LogisticRegression为例: 1].上传数据(如果用户有自己的数据可以略过本步,但是要确认数据格式一致) 找到发布包的data目录下的LogisticRegression测试数据 在hdfs上新建lr训练数据目录 hadoop fs -mkdir hdfs://my-nn:54310/test/lr_data 将数据文件上传到指定目录下 hadoop fs -put data/exampledata/LRLocalExampleData/a9a.train hdfs://my-nn:54310/test/lr_data 2].提交任务 在发布包的bin目录下有Angel的提交脚本angel-submit,使用它将任务提交到Hadoop集群 请务必注意提交集群中是否有充足的资源,如果按照下面的参数配置,启动任务至少需要6GB内存和3个vcore ```bsh ./angel-submit \ --angel.app.submit.class com.tencent.angel.ml.core.graphsubmit.GraphRunner \ --angel.train.data.path "hdfs://my-nn:54310/test/lr_data" \ --angel.log.path "hdfs://my-nn:54310/test/log" \ --angel.save.model.path "hdfs://my-nn:54310/test/model" \ --action.type train \ --ml.model.class.name com.tencent.angel.ml.classification.LogisticRegression \ --ml.epoch.num 10 \ --ml.data.type libsvm \ --ml.feature.index.range 1024 \ --angel.job.name LR_test \ --angel.am.memory.gb 2 \ --angel.worker.memory.gb 2 \ --angel.ps.memory.gb 2 ``` 参数含义如下:
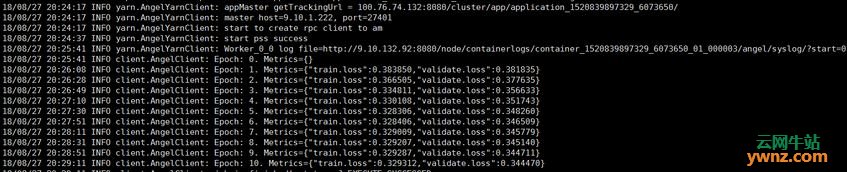
3.观察进度 任务提交之后,会在控制台打印出任务运行信息,如URL和迭代进度等,如下图所示:
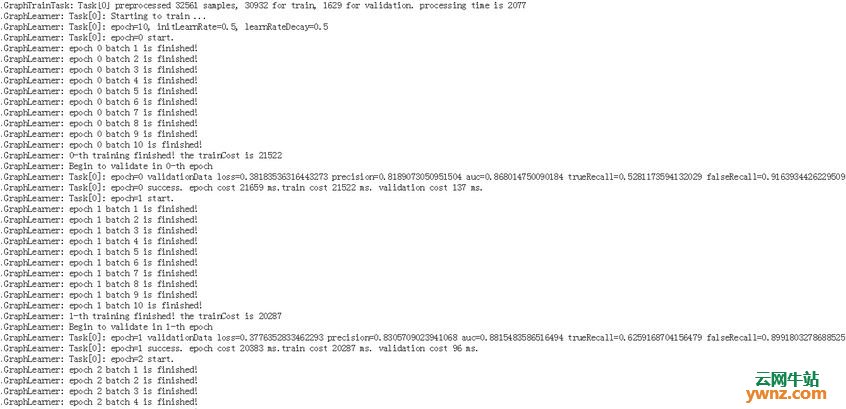
打开URL信息就可以看到Angel任务每一个组件的详细运行信息和算法相关日志:
目前的监控页面有点简陋,后续会进一步优化,围绕PS的本质,提高美观程度和用户可用度。
相关链接
相关主题 |