|
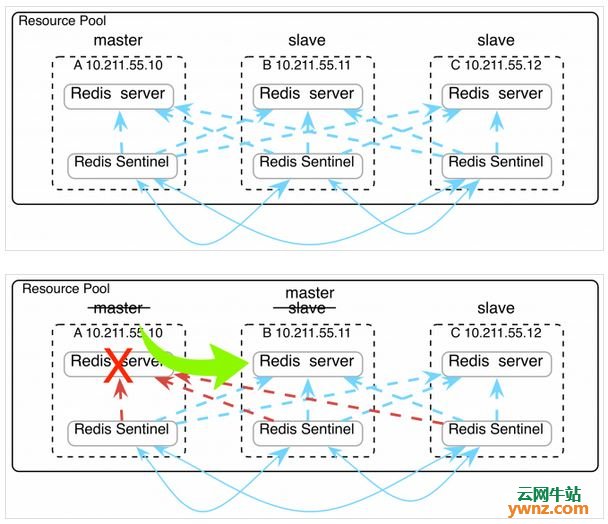
Redis Sentinel简介 Redis Sentinel主要用于实现Redis高可用的一套解决方案。Redis Sentinel由两个部分组成:由一个或者多个Sentinel实例组成Sentinel系统;由一个主Redis服务器(Master Redis)和多个从Redis服务器(Slave Redis)组成主从备份的Redis系统。 Sentinel系统本身是一个分布式的系统,它的作用是监视Redis服务器,在Master Redis下线时,自动将某个Slave Redis提升为新的主服务器。Redis系统由Master Redis处理客户端的命令请求,Slave Redis作为主服务器的备份而存在。
Redis Sentinel主要作用 监控(Monitoring):Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。 提醒(Notification):当被监控的某个Redis服务器出现问题时, Sentinel可以通过API向管理员或者其他应用程序发送通知。 自动故障迁移(Automatic failover):当一个主服务器不能正常工作时, Sentinel会开始一次自动故障迁移操作,它会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
Redis Sentinel系统架构图
Sentinel的原理并不复杂: 1.启动N个Sentinel实例,这些Sentinel实例会去监控你指定的Redis Master/Slaves。 2.当Redis Master节点挂掉后,Sentinel实例通过ping检测失败发现这种情况就认为该节点进入 SDOWN状态,也就是检测的Sentinel实例主观地(Subjectively)认为该Redis Master节点挂掉。 3.当一定数目(Quorum参数设定的Sentinel实例都认为该Master挂掉的情况下,该节点将转换进入ODOWN状态,也就是客观地(Objectively)挂掉的状态。 4.接下来Sentinel实例之间发起选举,选择其中一个Sentinel实例发起failover过程:从Slave中选择一台作为新的Master,让其它Slave从新的Master复制数据,并通过Pub/Sub发布事件。 5.使用者客户端从任意Sentinel实例获取Redis配置信息,并监听(可选)Sentinel发出的事件: SDOWN, ODOWN以及failover等,并做相应主从切换,Sentinel还扮演了服务发现的角色。 6.Sentinel的Leader选举采用的是Raft协议。
构建Redis Sentinel集群 Redis Sentinel环境准备
一个一主多从的Redis系统中,可以使用多个Sentinel进行监控任务以保证系统足够稳健。此时,不仅Sentinel会同时监控主数据库和从数据库,Sentinel之间也会相互监控。在这里,建议大家Sentinel至少部署三个,并且使用奇数个Sentinel。
安装Redis和Sentinel 在三台服务器上分别安装Redis和Sentinel。需要注意的是,如果要给Redis设置密码,需要在三个Redis的配置文件中设置相同的密码。 安装的Redis版本必须在2.8版本以上。 $ apt-get install redis-server redis-sentinel 同时可以参考如何在Ubuntu 18.04上从源代码安装Redis。
配置Redis和Sentinel 1.配置Redis 三台Redis主机配置类似,只是初次配置时角色不同。这里以主机dev-master-01为例,其它两台按实际情况修改就行了。 Redis默认会绑定到127.0.0.1,这里要在多台机器间通信,我们将它绑定到主机IP上。 $ vim /etc/redis/redis.conf bind 192.168.2.210 如果要给Redis设置密码,需要在三个Redis的配置文件中设置相同的密码。 $ vim /etc/redis/redis.conf requirepass "000000" 2.设置主从复制 在两个Slave Redis的配置文件中声明所从属的主数据库。 $ vim /etc/redis/redis.conf slaveof 192.168.2.210 6379 这里需要注意一点:当一个Master配置需要密码才能连接时,客户端和Slave在连接时都需要提供密码。Master通过requirepass设置自身的密码,不提供密码无法连接到这个Master。Slave通过masterauth来设置访问Master时的密码。 Sentinel可以切换主从数据库,主数据库可能会变成从数据库,所以三台机器上都需要同时设置requirepass和masterauth配置项。 $ vim /etc/redis/redis.conf requirepass "000000" masterauth "000000" 3.配置Sentinel redis-sentinel软件包中默认包含了一个名为sentinel.conf的文件,默认在/etc/redis/sentinel.conf。这里以主机dev-master-01为例,其它两台配置类似,按实际情况修改就行了。 运行一个Sentinel所需的最少配置如下所示: 运行:$ vim /etc/redis/sentinel.conf daemonize yes port 26379 bind 192.168.2.210 sentinel monitor redis-master 192.168.2.210 6379 2 sentinel down-after-milliseconds redis-master 5000 sentinel failover-timeout redis-master 180000 sentinel parallel-syncs redis-master 2 sentinel auth-pass redis-master 000000 sentinel notification-script redis-master /etc/redis/notify.sh sentinel client-reconfig-script mymaster /etc/redis/failover.sh logfile /var/log/redis/redis-sentinel.log 以上配置项说明: daemonize yes 以后台进程模式运行。 port 26379 Sentinel实例之间的通讯端口,该端口号默认为26379。 bind 192.168.2.210 Sentinel默认会绑定到127.0.0.1,这里要在多台机器间通信,我们将它绑定到主机IP上。 sentinel monitor redis-master 192.168.2.210 6379 2 Sentinel去监视一个名为redis-master的主服务器,这个主服务器的IP地址为192.168.2.210 ,端口号为6379。将这个主服务器判断为失效至少需要2个Sentinel同意,一般设置为N/2+1(N为Sentinel总数)。只要同意Sentinel的数量不达标,自动故障迁移就不会执行。 不过要注意,无论你设置要多少个Sentinel同意才能判断一个服务器失效, 一个Sentinel都需要获得系统中多数Sentinel的支持,才能发起一次自动故障迁移,并预留一个给定的配置纪元。(configuration Epoch ,一个配置纪元就是一个新主服务器配置的版本号)。 sentinel down-after-milliseconds redis-master 5000 down-after-milliseconds选项指定了Sentinel认为服务器已经断线所需的毫秒数。如果服务器在给定的毫秒数之内,没有返回Sentinel发送的PING命令的回复,或者返回一个错误,那么Sentinel将这个服务器标记为主观下线(subjectively down,简称SDOWN)。 不过只有一个Sentinel将服务器标记为主观下线并不一定会引起服务器的自动故障迁移,只有在足够数量的Sentinel都将一个服务器标记为主观下线之后,服务器才会被标记为客观下线(objectively down,简称ODOWN), 这时自动故障迁移才会执行。将服务器标记为客观下线所需的Sentinel数量由对主服务器的配置(sentinel monitor 参数)决定。 sentinel failover-timeout redis-master 180000 如果在多少毫秒内没有把宕掉的那台Master恢复,那Sentinel认为这是一次真正的宕机。在下一次选取时排除该宕掉的Master作为可用的节点,然后等待一定的设定值的毫秒数后再来探测该节点是否恢复,如果恢复就把它作为一台Slave加入Sentinel监测节点群,并在下一次切换时为他分配一个”选取号”。 sentinel parallel-syncs redis-master 2 parallel-syncs选项指定了在执行故障转移时,最多可以有多少个从服务器同时对新的主服务器进行同步。这个数字越小,完成故障转移所需的时间就越长。 如果从服务器被设置为允许使用过期数据集(slave-serve-stale-data选项), 那么你可能不希望所有从服务器都在同一时间向新的主服务器发送同步请求。因为尽管复制过程的绝大部分步骤都不会阻塞从服务器,但从服务器在载入主服务器发来的RDB文件时,仍然会造成从服务器在一段时间内不能处理命令请求。 如果全部从服务器一起对新的主服务器进行同步,那么就可能会造成所有从服务器在短时间内全部不可用的情况出现。你可以通过将这个值设为1来保证每次只有一个从服务器处于不能处理命令请求的状态。 sentinel auth-pass redis-master 000000 当Master设置了密码时,Sentinel连接Master和Slave时需要通过设置参数auth-pass配置相应密码。 sentinel notification-script redis-master /etc/redis/notify.sh 指定Sentinel检测到该监控的Redis实例failover时调用的报警脚本。脚本被允许执行的最大时间为60秒,超过这个时间脚本会被kill。该配置项可选,但线上系统建议配置。这里的通知脚本简单的记录一下failover事件。 # 创建通知脚本 运行:$ vim /etc/redis/notify.sh #! /bin/bash echo "master failovered at `date`" > /var/log/redis/redis_issues.log # 给脚本增加执行权限 $ chmod +x /etc/redis/notify.sh sentinel client-reconfig-script redis-master /etc/redis/failover.sh 指定Sentinel failover之后重配置客户端时执行的脚本,该配置项可选,但线上系统建议配置。 logfile /var/log/redis/redis-sentinel.log 日志文件所在位置,默认在/var/log/redis/redis-sentinel.log。
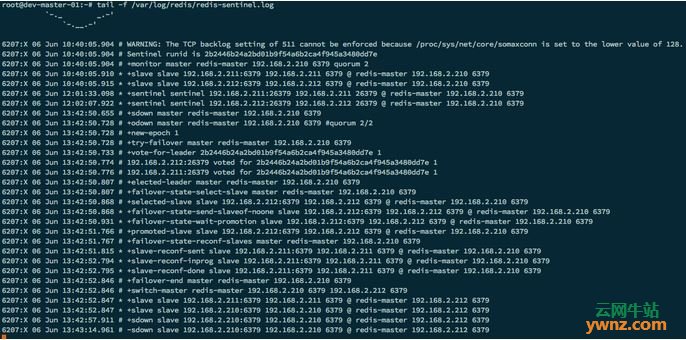
运行Sentinel 配置完Redis和Sentinel之后,按顺序启动各个角色。启动顺序如下:Master->Slave->Sentinel,要确保按照这个顺序依次启动。 1.启动Redis $ systemctl start redis 2.启动Sentinel 运行Sentinel有两种方式: 虽然Redis Sentinel有单独的软件安装包,但实际上它只是一个运行在特殊模式下的Redis实例。当前Redis Stable版已经自带了redis-sentinel这个工具。你可以在启动一个普通Redis实例时通过给定--sentinel选项来启动Redis Sentinel。 第一种:用单独的可执行文件redis-sentinel $ redis-sentinel /etc/redis/sentinel.conf 第二种:使用redis-server的–sentinel选项 $ redis-server /etc/redis/sentinel.conf --sentinel 以上两种方式,都必须指定一个Sentinel的配置文件sentinel.conf。需要确保配置文件是可写的,因为Sentinel会往配置文件里添加很多信息作为状态持久化,这是为了重启等情况下可以正确地恢复 Sentinel的状态。 当配置文件无法写入时,Sentinel会启动失败。Sentinel默认监听26379端口,所以运行前必须确定该端口没有被别的进程占用。 我们这里用redis-sentinel方式来启动: $ systemctl start redis-sentinel 3.测试Sentinel 启动成功后可以通过redis客户端工具查看当前Sentinel的信息,终端输入: 运行:$ redis-cli -p 26379 -h 192.168.2.210 INFO Sentinel # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:2 sentinel_scripts_queue_length:1 master0:name=redis-master,status=ok,address=192.168.2.210:6379,slaves=2,sentinels=1 Sentinel启动后会输出类似的日志: 运行:$ tail -f /var/log/redis/redis-sentinel.log 6207:X 06 Jun 10:40:05.904 # Sentinel runid is 2b2446b24a2bd01b9f54a6b2ca4f945a3480dd7e 6207:X 06 Jun 10:40:05.904 # +monitor master redis-master 192.168.2.210 6379 quorum 2 6207:X 06 Jun 10:40:05.910 * +slave slave 192.168.2.211:6379 192.168.2.211 6379 @ redis-master 192.168.2.210 6379 6207:X 06 Jun 10:40:05.915 * +slave slave 192.168.2.212:6379 192.168.2.212 6379 @ redis-master 192.168.2.210 6379 6207:X 06 Jun 12:01:33.098 * +sentinel sentinel 192.168.2.211:26379 192.168.2.211 26379 @ redis-master 192.168.2.210 6379 6207:X 06 Jun 12:02:07.922 * +sentinel sentinel 192.168.2.212:26379 192.168.2.212 26379 @ redis-master 192.168.2.210 637968.2.212:6379 192.168.2.212 6379 @ redis-master 192.168.2.210 6379 输出的结果表示开始监控redis-master集群,并输出集群的基本信息。+slave和+sentinel分别代表成功发现了从数据库和其他Sentinel。 4.查看sentinel.conf 重新打开sentinel.conf文件,发现Sentinel自动生成了一些信息,记录了监控过程中的状态变化。 运行:$ cat /etc/redis/sentinel.conf # Generated by CONFIG REWRITE maxclients 4064 sentinel leader-epoch redis-master 0 sentinel known-slave redis-master 192.168.2.212 6379 sentinel known-slave redis-master 192.168.2.211 6379 sentinel current-epoch 0 5.查看Sentinel监控的主从服务器 列出所有被监视的主服务器,以及这些主服务器的当前状态。 运行:$ redis-cli -p 26379 -h 192.168.2.210 192.168.2.210:26379> sentinel master redis-master 1) "name" 2) "redis-master" 3) "ip" 4) "192.168.2.210" 5) "port" 6) "6379" 7) "runid" 8) "02d88a6105ce3277745c1fc65b695887f165f302" 9) "flags" 10) "master" 11) "pending-commands" 12) "0" 13) "last-ping-sent" 14) "0" 15) "last-ok-ping-reply" 16) "1096" 17) "last-ping-reply" 18) "1096" 19) "down-after-milliseconds" 20) "5000" 21) "info-refresh" 22) "4732" 23) "role-reported" 24) "master" 25) "role-reported-time" 26) "667578" 27) "config-epoch" 28) "0" 29) "num-slaves" 30) "2" 31) "num-other-sentinels" 32) "0" 33) "quorum" 34) "2" 35) "failover-timeout" 36) "180000" 37) "parallel-syncs" 38) "2" 39) "notification-script" 40) "/etc/redis/notify.sh"
Sentinel验证 测试Failover 我们让dev-master-01主机上的redis-master主动休眠30秒来观察failover过程: $ redis-cli -p 6379 -h 192.168.2.210 -a 000000 DEBUG sleep 30 我们可以看到每个Sentinel进程都监控到Master挂掉,从sdown状态进入odown,然后选举了一个leader来进行failover,最终192.168.2.212成为新的Master, Sentinel的日志输出:
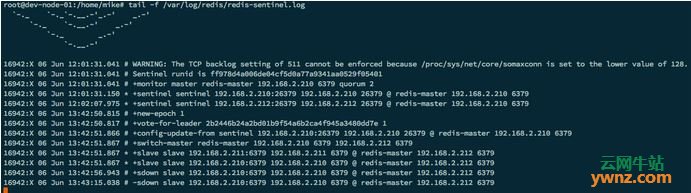
日志的几个主要事件 在Redis Master角色上主要有以下几个事件: 1.+sdown master redis-master 192.168.2.210 6379,发现Master检测失败,主观认为该节点挂掉,进入sdown状态。 2.+odown master redis-master 192.168.2.210 6379 #quorum 2/2,有两个Sentinel节点认为Master 6379挂掉,达到配置的quorum值2,因此认为Master已经客观挂掉,进入odown状态。 3.+try-failover master redis-master 192.168.2.210 6379,表示Sentine开始进行故障恢复。 4.+vote-for-leader 2b2446b24a2bd01b9f54a6b2ca4f945a3480dd7e 1,准备选举一个 Sentinel Leader来开始failover。 5.+failover-end master redis-master 192.168.2.210 6379,表示Sentinel完成故障修复,其中包括了Sentinel Leader的选举、备选从数据库的选择等较为复杂的过程。 6.+switch-master redis-master 192.168.2.210 6379 192.168.2.212 6379, 切换Master节点,failover完成。 7.-sdown slave 192.168.2.210:6379 192.168.2.210 6379 @ redis-master 192.168.2.212 6379,192.168.2.210休眠完成后,作为Slave挂载到192.168.2.212后面,可见Sentinel确实同时在监控Slave状态,并且挂掉的节点不会自动移除,而是继续监控。 在Redis Slave角色上主要有以下几个事件:
Redis Slave上大多数都和Redis Master上的事件类似,不同的是Redis Slave还多了一步配置更新。 +config-update-from sentinel 192.168.2.210:26379 192.168.2.210 26379 @ redis-master 192.168.2.210 6379
查看Sentinel配置文件变更 经过一次failover后,会发现Sentinel配置文件变更了以下一些内容。可以看到Sentinel将最新的集群状态写入了配置文件。 运行:$ cat /etc/redis/sentinel.conf # Generated by CONFIG REWRITE maxclients 4064 sentinel leader-epoch redis-master 1 sentinel known-slave redis-master 192.168.2.211 6379 sentinel known-slave redis-master 192.168.2.210 6379 sentinel known-sentinel redis-master 192.168.2.212 26379 bbf85fae74692d9527e77c5b0bb83a2b5db40dd2 sentinel known-sentinel redis-master 192.168.2.210 26379 2b2446b24a2bd01b9f54a6b2ca4f945a3480dd7e sentinel current-epoch 1
验证下三台主机上的角色 1.dev-node-02 以下输出信息,表明192.168.2.212上的Redis是Master角色。 运行:$ redis-cli -p 6379 -h 192.168.2.212 -a 000000 info Replication # Replication role:master connected_slaves:2 slave0:ip=192.168.2.211,port=6379,state=online,offset=2312008,lag=0 slave1:ip=192.168.2.210,port=6379,state=online,offset=2312008,lag=0 master_repl_offset:2312008 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1639828 repl_backlog_histlen:672181 2.dev-master-01 以下输出信息,表明192.168.2.210上的Redis是Slave角色。 运行:$ redis-cli -p 6379 -h 192.168.2.210 -a 000000 info Replication # Replication role:slave master_host:192.168.2.212 master_port:6379 master_link_status:up master_last_io_seconds_ago:0 master_sync_in_progress:0 slave_repl_offset:2222825 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:593455 repl_backlog_histlen:1048576 3.dev-node-01 以下输出信息,表明192.168.2.211上的Redis是Slave角色。 运行:$ redis-cli -p 6379 -h 192.168.2.211 -a 000000 info Replication # Replication role:slave master_host:192.168.2.212 master_port:6379 master_link_status:up master_last_io_seconds_ago:0 master_sync_in_progress:0 slave_repl_offset:2283392 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
Sentinel日常运维 Sentinel常用命令 以下列出的是Sentinel接受的命令: PING:返回PONG。 SENTINEL masters:列出所有被监视的主服务器,以及这些主服务器的当前状态。 SENTINEL master <master name>:用于查看监控的某个Redis Master信息,包括配置和状态等。 SENTINEL slaves <master name>:列出给定主服务器的所有从服务器,以及这些从服务器的当前状态。 SENTINEL sentinels <master name>:查看给定主服务器的Sentinel实例列表及其状态。 SENTINEL get-master-addr-by-name <master name>:返回给定名字的主服务器的IP地址和端口号。 如果这个主服务器正在执行故障转移操作,或者针对这个主服务器的故障转移操作已经完成,那么这个命令返回新的主服务器的IP地址和端口号。 SENTINEL reset <pattern>:重置所有名字和给定模式pattern相匹配的主服务器。pattern 参数是一个Glob风格的模式。重置操作清除主服务器目前的所有状态,包括正在执行中的故障转移,并移除目前已经发现和关联的,主服务器的所有从服务器和Sentinel。 SENTINEL failover <master name>:当主服务器失效时, 在不询问其他Sentinel意见的情况下,强制开始一次自动故障迁移(不过发起故障转移的Sentinel会向其他Sentinel发送一个新的配置,其他Sentinel会根据这个配置进行相应的更新)。 SENTINEL reset <pattern>:强制重设所有监控的Master状态,清除已知的Slave和Sentinel实例信息,重新获取并生成配置文件。 SENTINEL failover <master name>:强制发起一次某个Master的failover,如果该Master不可访问的话。 SENTINEL ckquorum <master name>:检测Sentinel配置是否合理,failover的条件是否可能满足,主要用来检测你的Sentinel配置是否正常。 SENTINEL flushconfig:强制Sentinel重写所有配置信息到配置文件。 SENTINEL is-master-down-by-addr <ip> <port>:一个Sentinel可以通过向另一个Sentinel发送SENTINEL is-master-down-by-addr命令来询问对方是否认为给定的服务器已下线。
增加和移除监控以及修改配置参数 SENTINEL MONITOR <name> <ip> <port> <quorum> SENTINEL REMOVE <name> SENTINEL SET <name> <option> <value>
增加和移除Sentinel 增加新的Sentinel实例非常简单,修改好配置文件,启动即可,其他Sentinel会自动发现该实例并加入集群。如果要批量启动一批Sentinel节点,最好以30秒的间隔一个一个启动为好,这样能确保整个 Sentinel集群的大多数能够及时感知到新节点,满足当时可能发生的选举条件。 移除一个Sentinel实例会相对麻烦一些,因为Sentinel不会忘记已经感知到的Sentinel实例,所以最好按照下列步骤来处理: 停止将要移除的sentinel进程。 给其余的sentinel进程发送SENTINEL RESET *命令来重置状态,忘记将要移除的sentinel,每个进程之间间隔30秒。 确保所有sentinel对于当前存货的sentinel数量达成一致,可以通过SENTINEL MASTER <mastername>命令来观察,或者查看配置文件。
生产环境推荐 对于一个最小集群,Redis应该是一个Master带上两个Slave,并且开启下列选项: min-slaves-to-write 1 min-slaves-max-lag 10 这样能保证写入Master的同时至少写入一个Slave,如果出现网络分区阻隔并发生failover的时候,可以保证写入的数据最终一致而不是丢失,写入老的Master会直接失败。 Slave可以适当设置优先级,除了0之外(0表示永远不提升为Master),越小的优先级,越有可能被提示为Master。如果Slave分布在多个机房,可以考虑将和Master同一个机房的Slave的优先级设置的更低以提升他被选为新的Master的可能性。 考虑到可用性和选举的需要,Sentinel进程至少为3个,推荐为5个。如果有网络分区,应当适当分布(比如2个在A机房, 2个在B机房,一个在C机房)等。
客户端实现 客户端从过去直接连接Redis,变成: 1.先连接一个Sentinel实例 2.使用 SENTINEL get-master-addr-by-name master-name 获取Redis地址信息。 3.连接返回的Redis地址信息,通过ROLE命令查询是否是Master。如果是,连接进入正常的服务环节。否则应该断开重新查询。 4.(可选)客户端可以通过SENTINEL sentinels <master-name>来更新自己的Sentinel实例列表。 当Sentinel发起failover后,切换了新的Master,Sentinel会发送 CLIENT KILL TYPE normal命令给客户端,客户端需要主动断开对老的Master的链接,然后重新查询新的Master地址,再重复走上面的流程。这样的方式仍然相对不够实时,可以通过Sentinel提供的Pub/Sub来更快地监听到failover事件,加快重连。 如果需要实现读写分离,读走Slave,那可以走SENTINEL slaves <master name> 来查询Slave列表并连接。
其他 由于Redis是异步复制,所以Sentinel其实无法达到强一致性,它承诺的是最终一致性:最后一次failover的Redis Master赢者通吃,其他Slave的数据将被丢弃,重新从新的Master复制数据。此外还有前面提到的分区带来的一致性问题。 其次,Sentinel的选举算法依赖时间,因此要确保所有机器的时间同步,如果发现时间不一致,Sentinel实现了一个TITL模式来保护系统的可用性。
相关主题 |