|
本文介绍在CentOS 7/Ubuntu 18.04中操作系统安装Apache Hadoop的方法。
一、更新系统 1、针对CentOS 7: 我建议你安装在安全专用网络中的服务器上,并禁用SELinux和Firewalld: sudo systemctl disable --now firewalld sudo setenforce 0 sudo sed -i 's/^SELINUX=.*/SELINUX=permissive/g' /etc/selinux/config cat /etc/selinux/config | grep SELINUX= | grep -v '#' 在开始部署Hadoop之前更新CentOS 7系统: sudo yum -y install epel-release sudo yum -y install vim wget curl bash-completion sudo yum -y update sudo reboot 2、针对Ubuntu 18.04: 运行以下命令更新Ubuntu 18.04系统: sudo apt update sudo apt -y upgrade sudo reboot
二、安装Java 1、如果CentOS 7服务器上缺少Java,请安装: sudo yum -y install java-1.8.0-openjdk java-1.8.0-openjdk-devel 验证Java已否成功安装: $ java -version java version "1.8.0_201" 设置JAVA_HOME变量: cat <<EOF | sudo tee /etc/profile.d/hadoop_java.sh export JAVA_HOME=$(dirname $(dirname $(readlink $(readlink $(which javac))))) export PATH=\$PATH:\$JAVA_HOME/bin EOF 更新$PATH和设置: source /etc/profile.d/hadoop_java.sh 然后测试: $ echo $JAVA_HOME /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.201.b09-2.el7_6.x86_64 2、在Ubuntu 18.04下安装Java: sudo add-apt-repository ppa:webupd8team/java sudo apt update sudo apt -y install oracle-java8-installer oracle-java8-set-default 参考:使用PPA在Ubuntu、Linux Mint或Debian系统中安装java 11。 验证版本: $ java -version java version "1.8.0_201" 设置JAVA_HOME变量、更新$PATH和设置、测试方法请参考以上的CentOS 7操作步骤。
三、为Hadoop创建用户帐户 让我们为Hadoop创建一个单独的用户,这样我们就可以在Hadoop文件系统和Unix文件系统之间进行隔离。 1、针对CentOS 7: sudo adduser hadoop passwd hadoop sudo usermod -aG wheel hadoop 2、针对Ubuntu 18.04: sudo adduser hadoop sudo usermod -aG sudo hadoop 添加用户后,为用户生成SS密钥对: $ sudo su - hadoop $ ssh-keygen -t rsa
将此用户的密钥添加到授权的ssh密钥列表中: cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys 验证你是否可以使用添加的密钥进行ssh: hadoop@hbase:~$ ssh localhost The authenticity of host 'localhost (::1)' can't be established. ECDSA key fingerprint is SHA256:WTqP642Xijk3xtTb/zt32o0Q7PqYlxzwX+H/B72z4P4. ECDSA key fingerprint is MD5:47:dc:17:78:63:f7:bc:12:72:70:4b:e3:2f:8a:c3:8d. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts. Last login: Sun Apr 7 12:47:16 2019 hadoop@hbase:~$ exit logout Connection to localhost closed.
四、下载并安装Hadoop 当前要安装的版本是3.1.2: wget https://www-eu.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz 注:Apache Hadoop下载地址。 提取文件: tar -xzvf hadoop-3.1.2.tar.gz 将生成的目录移动到/usr/local/hadoop: rm hadoop-3.1.2.tar.gz sudo mv hadoop-3.1.2/ /usr/local/hadoop 设置HADOOP_HOME并将带有Hadoop二进制文件的目录添加到$PATH: cat <<EOF | sudo tee /etc/profile.d/hadoop_java.sh export JAVA_HOME=$(dirname $(dirname $(readlink $(readlink $(which javac))))) export HADOOP_HOME=/usr/local/hadoop export HADOOP_HDFS_HOME=\$HADOOP_HOME export HADOOP_MAPRED_HOME=\$HADOOP_HOME export YARN_HOME=\$HADOOP_HOME export HADOOP_COMMON_HOME=\$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=\$HADOOP_HOME/lib/native export PATH=\$PATH:\$JAVA_HOME/bin:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin EOF 源文件: source /etc/profile.d/hadoop_java.sh 确认Hadoop版本: $ hadoop version Hadoop 3.1.2 Source code repository https://github.com/apache/hadoop.git -r 1019dde65bcf12e05ef48ac71e84550d589e5d9a Compiled by sunilg on 2019-01-29T01:39Z Compiled with protoc 2.5.0 From source with checksum 64b8bdd4ca6e77cce75a93eb09ab2a9 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.1.2.jar
五、配置Hadoop 所有Hadoop配置都位于/usr/local/hadoop/etc/hadoop/目录下:
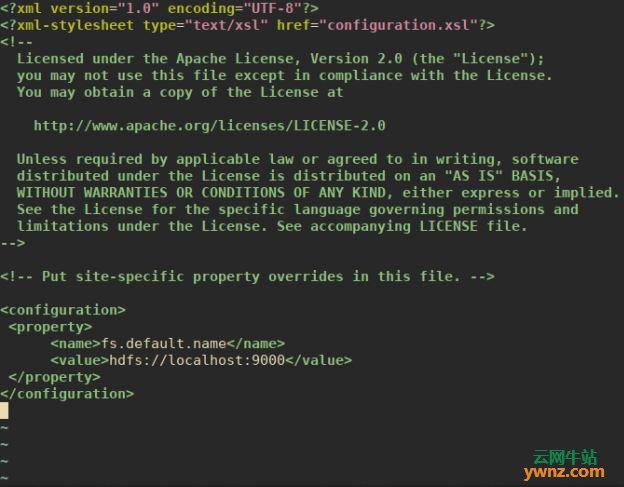
需要修改许多配置文件以在CentOS 7/Ubuntu 18.04上完成Hadoop安装。 首先在shell脚本hadoop-env.sh中编辑JAVA_HOME: $ sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh # Set JAVA_HOME - Line 54 export JAVA_HOME=$(dirname $(dirname $(readlink $(readlink $(which javac))))) 注:上面的配置针对CentOS 7,如果是Ubuntu 18.04则把export JAVA_HOME=$(dirname $(dirname $(readlink $(readlink $(which javac)))))改成export JAVA_HOME=/usr/lib/jvm/java-8-oracle。 然后进行相关的配置。 1、core-site.xml core-site.xml文件包含启动时使用的Hadoop集群信息,这些属性包括:用于Hadoop实例的端口号、为文件系统分配的内存、数据存储的内存限制、读/写缓冲区的大小。 打开core-site.xml: sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml 在<configuration>和</configuration>标记之间添加以下属性: <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> <description>The default file system URI</description> </property> </configuration>
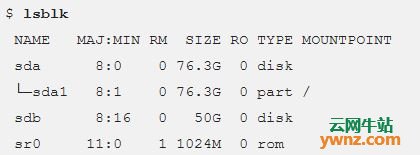
2、hdfs-site.xml 需要为要在群集中使用的每个主机配置此文件,该文件包含:本地文件系统上的namenode和datanode路径、复制数据的值。 在此设置中,我想将Hadoop基础结构存储在辅助磁盘 - /dev/sdb中: $ lsblk
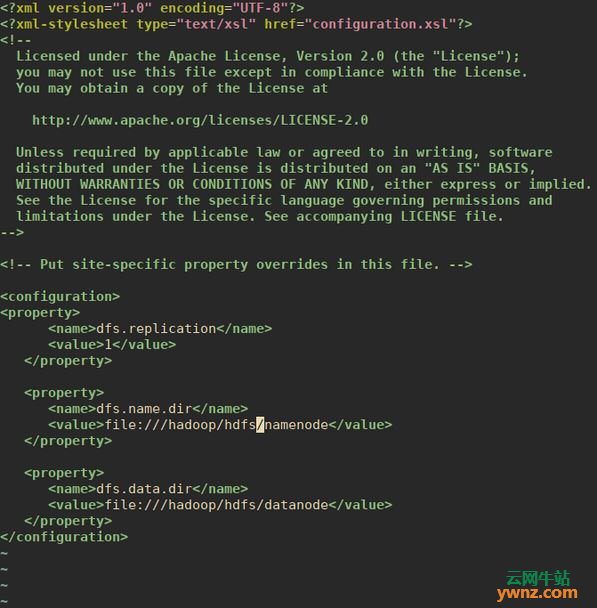
我将这个磁盘分区并挂载到/ hadoop目录: sudo parted -s -- /dev/sdb mklabel gpt sudo parted -s -a optimal -- /dev/sdb mkpart primary 0% 100% sudo parted -s -- /dev/sdb align-check optimal 1 sudo mkfs.xfs /dev/sdb1 sudo mkdir /hadoop echo "/dev/sdb1 /hadoop xfs defaults 0 0" | sudo tee -a /etc/fstab sudo mount -a 确认: $ df -hT | grep /dev/sdb1 /dev/sdb1 xfs 50G 33M 50G 1% /hadoop 为namenode和datanode创建目录: sudo mkdir -p /hadoop/hdfs/{namenode,datanode} 将所有权设置为hadoop用户和组: sudo chown -R hadoop:hadoop /hadoop 现在打开文件: sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml 然后在<configuration>和</configuration>标记之间添加以下属性: <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///hadoop/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///hadoop/hdfs/datanode</value> </property> </configuration>
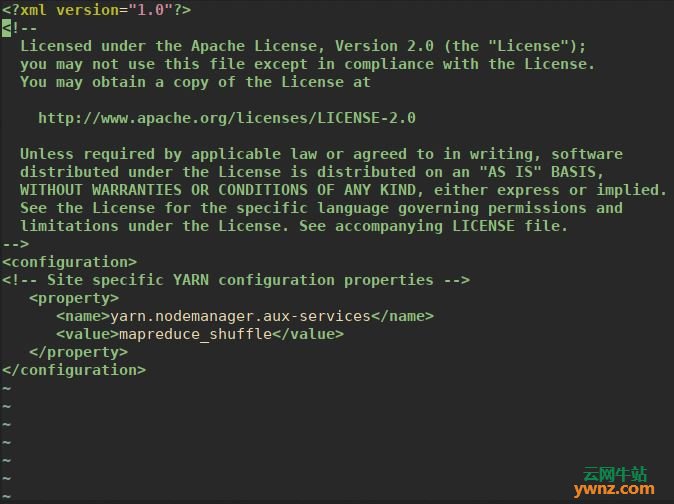
3、mapred-site.xml 这是设置要使用MapReduce框架的地方: sudo vim /usr/local/hadoop/etc/hadoop/mapred-site.xml 设置如下: <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> 4、yarn-site.xml 此文件中的设置将覆盖Hadoop yarn的配置,它定义了资源管理和作业调度逻辑: sudo vim /usr/local/hadoop/etc/hadoop/yarn-site.xml 增加: <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
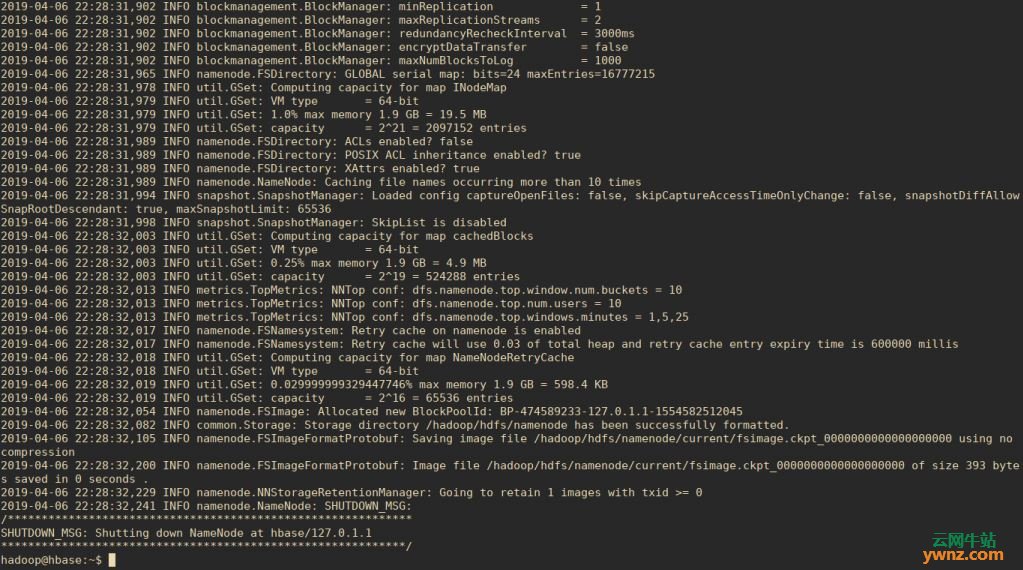
六、验证Hadoop配置 初始化Hadoop Infrastructure存储: sudo su - hadoop hdfs namenode -format 见下面的输出:
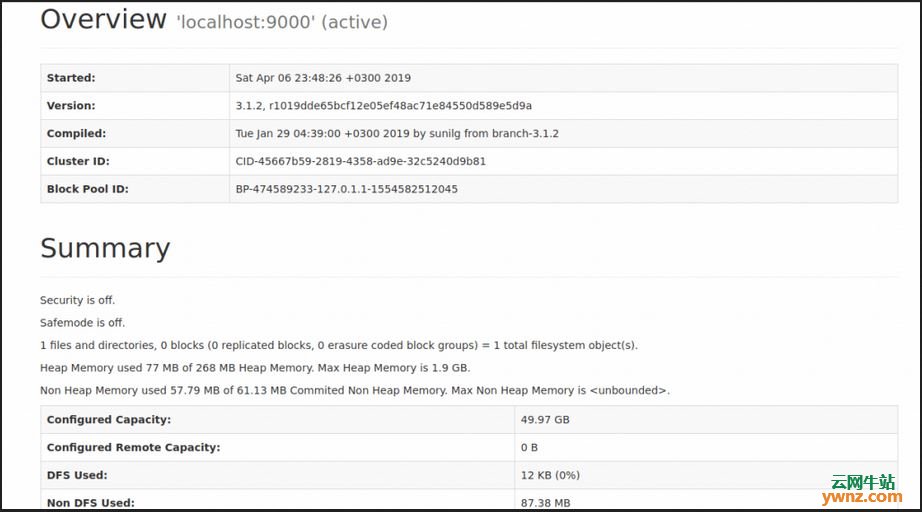
测试HDFS配置: $ start-dfs.sh Starting namenodes on [localhost] Starting datanodes Starting secondary namenodes [hbase] hbase: Warning: Permanently added 'hbase' (ECDSA) to the list of known hosts. 最后验证YARN配置: $ start-yarn.sh Starting resourcemanager Starting nodemanagers Hadoop 3.x defult Web UI端口: NameNode - 默认HTTP端口为9870。 ResourceManager - 默认HTTP端口为8088。 MapReduce JobHistory Server - 默认HTTP端口是19888。 可以使用以下方法检查hadoop使用的端口: $ ss -tunelp | grep java 访问地址http://ServerIP:9870上的Hadoop Web Dashboard:
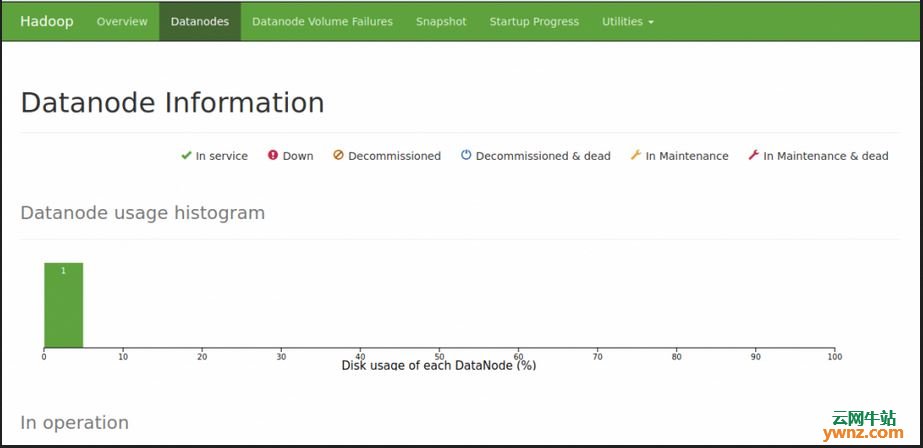
在http://ServerIP:8088上检查Hadoop集群页面:
测试以查看是否可以创建目录: $ hadoop fs -mkdir /test $ hadoop fs -ls / Found 1 items drwxr-xr-x - hadoop supergroup 0 2019-04-07 10:23 /test 停止Hadoop服务的方法,使用命令: $ stop-dfs.sh $ stop-yarn.sh 至此,Hadoop配置完成。 注:如果需要在CentOS 7下安装HBase请参考在Ubuntu 18.04操作系统中安装HBase的方法。
相关主题 |