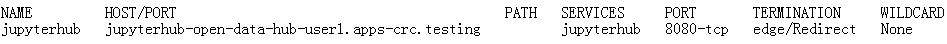|
是否想在OpenShift 4.1+上尝试复合解决方案?物理Fedora服务器上的CodeReady容器(CRC)是一个不错的选择,它可以让你:配置可用于CRC/OpenShift的RAM(这是关键,因为我们将部署机器学习,更改数据捕获,过程自动化和其他具有大量内存需求的解决方案)、避免在笔记本电脑上安装任何程序、标准化(在Fedora 30上),以便每次都能获得相同的结果。首先在Fedora 30物理服务器上安装CRC和Ansible Agnostic Deployer(AgnosticD),然后,你将使用AgnosticD在CRC创建的OpenShift 4.1环境中部署Open Data Hub,让我们开始吧。
设置CodeReady容器 $ dnf config-manager --set-enabled fedora $ su -c 'dnf -y install git wget tar qemu-kvm libvirt NetworkManager jq libselinux-python' $ sudo systemctl enable --now libvirtd 我们还要添加一个用户: $ sudo adduser demouser $ sudo passwd demouser $ sudo usermod -aG wheel demouser 下载并解压缩CodeReady容器: $ su demouser $ cd /home/demouser $ wget https://mirror.openshift.com/pub/openshift-v4/clients/crc/1.0.0-beta.3/crc-linux-amd64.tar.xz $ tar -xvf crc-linux-amd64.tar.xz $ cd crc-linux-1.0.0-beta.3-amd64/ $ sudo cp ./crc /usr/bin 根据物理服务器上的可用资源,为CRC设置可用的内存,例如,在大约100GB的物理服务器上,可以按以下方式为CRC分配80G: $ crc config set memory 81920 $ crc setup 你需要从https://cloud.redhat.com/openshift/install/metal/user-provisioned获取安全信息: $ crc start 就是这样,你现在可以登录到OpenShift环境: eval $(crc oc-env) && oc login -u kubeadmin -p <password> https://api.crc.testing:6443
设置Ansible Agnostic Deployer https://github.com/redhat-cop/agnosticd是一个全自动的两阶段部署程序,部署它: $ su demouser $ cd /home/demouser $ git clone https://github.com/redhat-cop/agnosticd.git $ cd agnosticd/ansible $ python -m pip install --upgrade --trusted-host files.pythonhosted.org -r requirements.txt $ python3 -m pip install --upgrade --trusted-host files.pythonhosted.org -r requirements.txt $ pip3 install kubernetes $ pip3 install openshift $ pip install kubernetes $ pip install openshift
在支持代码的容器上设置开放数据中心 Open Data Hub是一个基于OpenShift和Kafka/Strimzi的机器学习即服务平台,它集成了一系列开源项目。 首先,创建具有以下内容的Ansible库存文件(参考:详细介绍使用Ansible来实现网络自动化): $ cat inventory $ 127.0.0.1 ansible_connection=local 设置WORKLOAD环境变量,以便Ansible Agnostic Deployer知道我们要部署Open Data Hub: $ export WORKLOAD="ocp4-workload-open-data-hub" $ sudo cp /usr/local/bin/ansible-playbook /usr/bin/ansible-playbook 我们仅部署一个Open Data Hub项目,因此将user_count设置为1,你可以通过设置user_count为许多学生设置工作坊。 将为每个学生创建一个OpenShift项目(在本例中为Open Data Hub): $ eval $(crc oc-env) && oc login -u kubeadmin -p <password> https://api.crc.testing:6443 $ ansible-playbook -i inventory ./configs/ocp-workloads/ocp-workload.yml -e"ocp_workload=${WORKLOAD}" -e"ACTION=create" -e"user_count=1" -e"ocp_username=kubeadmin" -e"ansible_become_pass=<password>" -e"silent=False" $ oc project open-data-hub-user1 $ oc get route
在脸的笔记本电脑上,将jupyterhub-open-data-hub-user1.apps-crc.testing添加到/etc/hosts文件中,例如: 127.0.0.1 localhost fedora30 console-openshift-console.apps-crc.testing oauth-openshift.apps-crc.testing mapit-app-management.apps-crc.testing mapit-spring-pipeline-demo.apps-crc.testing jupyterhub-open-data-hub-user1.apps-crc.testing jupyterhub-open-data-hub-user1.apps-crc.testing 在笔记本电脑上: $ sudo ssh marc@fedora30 -L 443:jupyterhub-open-data-hub-user1.apps-crc.testing:443 你现在可以浏览到https://jupyterhub-open-data-hub-user1.apps-crc.testing/。 现在我们已经准备好开放数据中心,你可以在上面部署一些实用的东西,例如,你可以部署IBM的Qiskit开源框架进行量子计算。 你还可以为流程自动化,变更数据捕获,Camel集成和3scale API管理部署大量其他有用的工具。
相关主题 |